

Anuncio

¡Hola a todos! Antes de nada me gustaría presentarme, me llamo Víctor y soy ingeniero informático y desarrollador Android freelance. Empecé a interesarme por el SEO en 2019 y poco a poco he intentado formarme y aplicar mis conocimientos técnicos para probar cosas e intentar posicionar de la forma más fácil posible. Podéis ver mi perfil en linkedin aquí.
También tengo un blog en el que voy contando mis aprendizajes de la manera más didáctica posible, os presento Aprendiz De Seo. Y bueno, por último quiero darle las gracias a Bruno por invitarme a su «casa» y dejarme hacer este pequeño tutorial de scrapping con python. Como primera anotación quiero decir que más que aprender exactamente lo que os voy a enseñar tenéis que intentar quedaros con la mecánica; todo esto lo explicaré lo más detalladamente que pueda, pero siempre quedarán los comentarios para ir haciendo los ajustes necesarios.
¿Estáis listos? Yo no mucho pero creo que poco a poco irá saliendo. ¡Vamos allá!
Índice de contenidos
¿Qué es Python?
Para los que anden un poco perdidos merece la pena deterse aquí unos instantes: python es un lenguaje de programación que tiene más años que un bancal pero que sigue funcionando divinamente para ciertas tareas, como el análisis de datos. Esto es así porque la cantidad de librerías adicionales que se han escrito todos estos años es enorme y tenemos la gran ventaja de que las podemos utilizar gratis.
¿Cómo instalar Python?
Este punto depende del sistema operativo que uno tenga, como supongo que la mayoría tendrá Windows o un Mac, os dejo un par de tutoriales por aquí para que podáis instalarlo en vuestros sistemas; yo utilizo Linux, por lo que puede ser que veáis algunas cosas que os resulten un poco raras, ¡pero todo funcionará exactamente igual!
- Instalar Python en Windows: también indica cómo instalar VSCode. Visual Studio es un editor de texto que está optimizado para programar. El código que pondré se puede escribir en cualquier editor de texto, lo único que hay que hacer es guardarlo con la extensión adecuada (.py). Podéis instalar VSCode si queréis.
- Instalar Python en Mac.
Hay que instalar un paquete más que se llama pip, aquí os dejo una guía para instalarlo en windows.
Vamos a necesitar la librería BeautifulSoup, así que cuando tengamos pip instalado, en la consola escribiremos: pip install beautifulsoup4.
Consideraciones al programar con Python
Este lenguaje de programación, a mi modo de ver, tiene dos particularidades fundamentales que conviene tener presentes para luego desarrollar vuestros propios scripts (programas).
- La indentación (las instrucciones que van tabuladas) es fundamental.
- No se pone «;» (punto y coma) después de cada instrucción.
Bien, pues sin más dilación vamos con el ejemplo práctico.
Scrapear un listado de empresas con Python
Para este ejemplo busqué una web que pareciera fácil de scrapear y con datos que también sirvieran para una web de verdad. Así que pensé en hacer mi propio directorio de empresas de Navarra y ataqué esta: https://www.informa.es/directorio-empresas/Comunidad_NAVARRA.html (Si es tuya, lo siento mucho, es por motivos didácticos y prometo que fue al azar totalmente).
Bien, lo primero que hay que tener en cuenta es que para scrapear vamos a tener que buscar patrones en el código HTML de la página, y así indicarle al programa dónde tiene que buscar exactamente el dato.
Encontrar todas las URL que nos interesan
En la página de informa.es lo que vemos es que tienen las empresas de Navarra separadas en páginas y en cada una de ellas muestran 20 enlaces a las fichas de las empresas. Lo que nos interesa son los datos de la ficha, pero primero tenemos que conseguir el listado de URLS que queremos.
 Nota: Esto funciona así en este caso en concreto, pero en muchos otros casos bastará con encontrar las URLs del sitemap.
Nota: Esto funciona así en este caso en concreto, pero en muchos otros casos bastará con encontrar las URLs del sitemap.
Buscar los elementos en el código HTML
Con esta información, miramos el código fuente de la página (esto lo podemos hacer clicando con el botón derecho en el código que nos interesa y dándole a «Inspeccionar elemento») y vemos cómo está estructurado el HTML de la misma, y lo que es más importante, ver en qué elementos HTML está alojada la información que nos interesa. En este ejemplo concreto vemos lo siguiente:
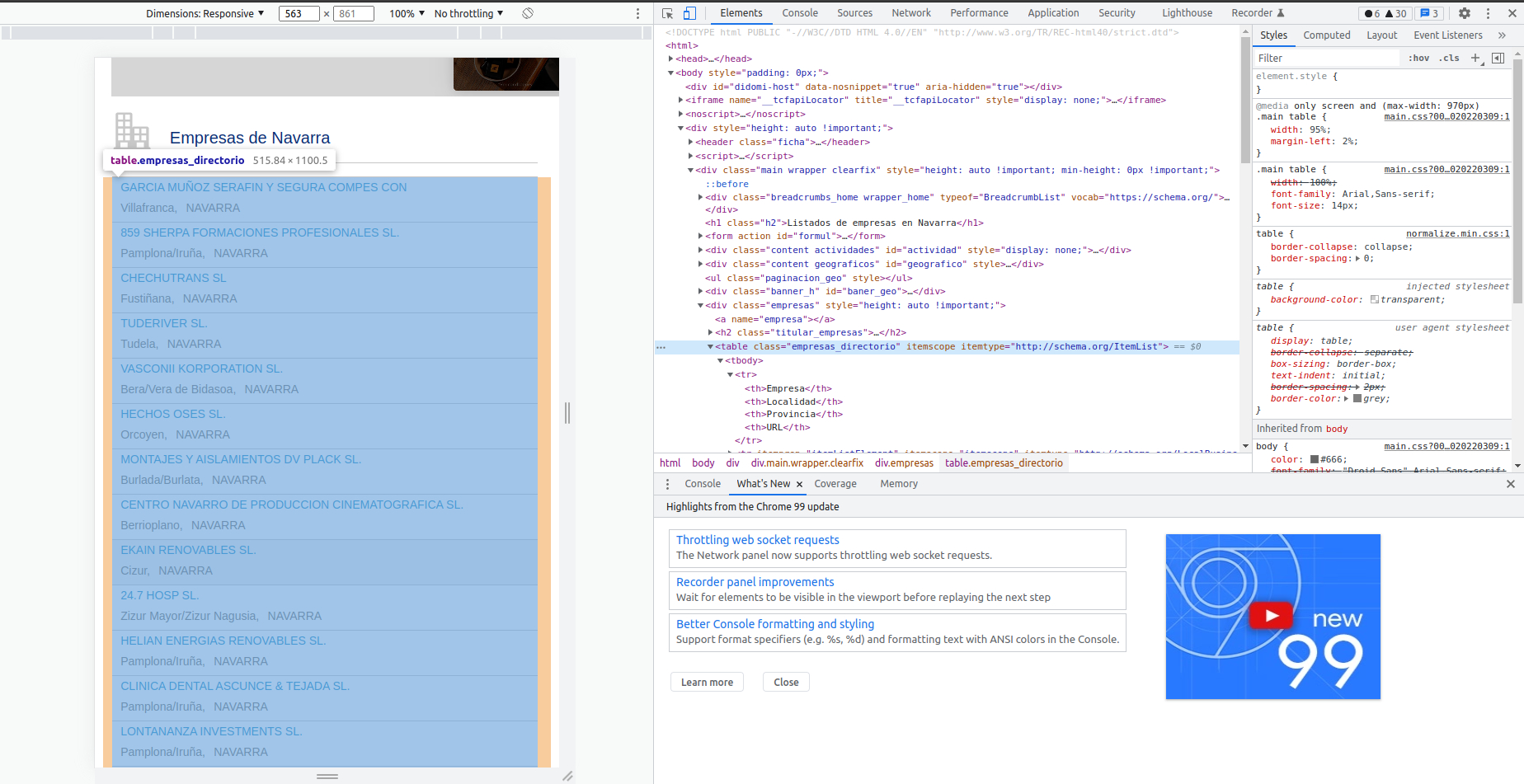
¡Bingo! Está en un elemento <table> (veis que pasando el ratón por encima del código se sombrea a la izquierda el bloque que engloba, por eso al pasar el cursos por encima del elemento «table» se nos sombrea toda la tabla). Si nos fijamos mejor, la tabla tiene una clase de css que es «empresas_directorio», esto es importante tenerlo en cuenta para después. Perfecto, ya sabemos que tenemos que buscar en la tabla. Lo bueno de las tablas es que tienen elementos <tr> que engloban toda la fila («tr» es table row). Así pues, si miramos con detenimiento cada uno de los <tr> de la tabla vemos lo siguiente:
- El primero no nos sirve, pues nos pone las cabeceras: empresa, localidad, provincia y URL. Descartaremos pues el primer elemento <tr> en la tabla.
- Dentro de cada <tr> hay varios elementos <td> que son los que tienen los datos, nos interesa uno cuya clase es «nom_empresa», ahí hay un elemento <a> (enlace) y su atributo «href» es el que tiene la ansiada URL.
Vamos a verlo con la imagen:

Pues nada, ya lo tenemos casi todo para sacar el listado de URLs, ahora nos falta el último detalle… ¿cuántas paginaciones hay?
Encontrar el número de paginaciones
Como hemos dicho, hay varias empresas en cada paginación, pero necesitamos saber cuántas URLs de listados tenemos que scrapear. Para eso, yo suelo hacer un pequeño truco que no es una genialidad, pero que sirve a fin de cuentas. Yo le doy al botón de «siguiente» y me fijo en la siguiente URL. Veamos qué nos ofrece:
URL original: https://www.informa.es/directorio-empresas/Comunidad_NAVARRA.html
URL después de darle al botón: https://www.informa.es/directorio-empresas/Comunidad_NAVARRA/Empresas-2.html#empresa
Vemos que la diferencia es que pone «Empresas-X».html#empresa, si seguís probando (con el botón de siguiente o modificando el número directamente en la URL), podéis ver cuál es la última. A mí me sale la 50. ¡Ah! Y si ponéis un 1 sale la principal, así que ya tenemos todo para el script.
Programar el script para buscar en el listado
Recapitulemos:
- Tenemos que buscar en las páginas de la forma https://www.informa.es/directorio-empresas/Comunidad_NAVARRA/Empresas-XX.html#empresa, donde «XX» es un número entre 1 y 50.
- En cada una de esas URLs vamos a buscar la información en el primer elemento <table> (hay otra tabla debajo pero no nos interesa).
- Dentro de la tabla, obviaremos la primera fila y nos concentraremos en el resto de <tr>.
- En estos TR, buscaremos el elemento <a> del <td> de la clase «nom_empresa» y justo en ese <a> sacaremos el atributo «href».
Fácil, ¿no? Es posible que toda esta información sea algo abrumante al principio; pero si le dáis un par de leídas más, intentando seguir el razonamiento, yo creo que estará perfectamente claro y esto es lo más difícil, entender el razonamiento a seguir. Lo otro es código y sale con la práctica.
Bueno, pues este es el código del script que he hecho para este caso (lo explicaré línea a línea):
Anuncio

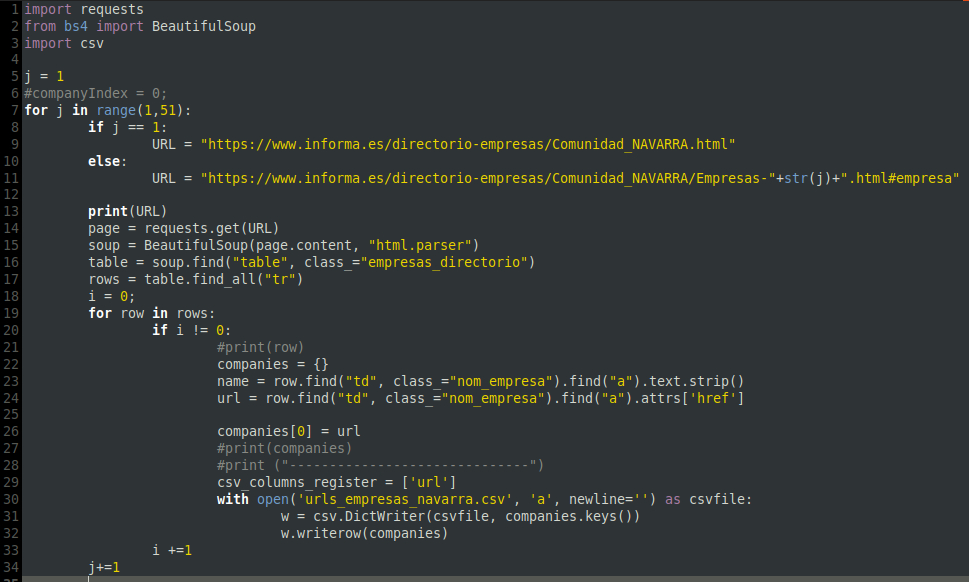
Podéis descargarlo de aquí. Os recomiendo crear un fichero de texto nuevo, pegar el contenido y renombrarlo como «empresas.py».
Vamos a analizar las partes más interesantes del código:
- Líneas 1 a 4: son instrucciones para el uso de librerías externas, en este caso necesitamos una para hacer consultas a URLs externas (requests), el BeautifulSoup que es la librería que nos da la posibilidad de encontrar la información en las etiquetas HTML y, por último, la librería csv que nos va a permitir leer y escribir ficheros csv.
- La siguiente línea interesante es la 8: en esta lo que estamos indicando es que el código que va «dentro», es decir, con una tabulación más «hacia dentro» se tiene que repetir para cada valor de j entre 1 y 51, es decir, 51 veces (j se incrementa en cada iteración). Así conseguiremos generar las 50 URL que tenemos que scrapear.
- En la línea 9 preguntamos por el valor de j, que será 1 en la primera vuelta del bucle, si es 1 la URL a atacar es la primera, pero si no es 1, tendremos que generar la URL que vamos a scrapear añadiéndole el valor actual de j. La variable j se incrementa en cada iteración (ver línea 35) con lo que cada vez que se scrapee una página, el valor de j se incrementará en 1 y podremos construir las URLs de las páginas adicionales a la primera.
- Líneas 14 y 15: son las que hacen que nos descarguemos el código de la URL que hemos generado justo antes y podamos buscar etiquetas HTML dentro de la página, esto es lo que hace BeautifulSoup. Digamos que ahora tendríamos el contenido de la URL descargada en la variable «soup».
- Línea 16: Con esto le decimos que dentro del código de la página (variable soup) busque una <table> cuya clase sea «empresas_directorio», tal y como vimos anteriormente en este tutorial. Además, ese contenido (es decir, el código de la tabla en sí) lo vamos a guardar en una variable nueva que se llama «table».
- Línea 17: dentro de la tabla buscamos todas las etiquetas <tr>.
- Líneas 18, 19 y 20: aquí lo que hago es un pequeño truco para «saltarme» la primera <tr> (como dijimos, esa no nos interesa), así que lo que hago es llevar un contador de cuántas TRs he analizado hasta ahora (la variable i) y si la i no es la 0 (línea 20) entonces puedo proceder a seguir buscando información. De nuevo , en la línea 19 marcamos un bucle que se ejecutará tantas veces como etiquetas <tr> haya en la tabla.
- Líneas 22, 23 y 24: creo un diccionario que se llama companies y que me sirve solo para estructurar los datos de forma que los pueda guardar en el CSV más fácilmente. Obtengo en la línea 23 el nombre de la empresa y la url, buscando el atributo «href» de la etiqueta <a> en la <td> cuya clase sea «nom_empresa» de la <tr> que estoy analizando. Luego no usaré el nombre para nada, pero quería dejarlo de ejemplo para que veáis cómo se saca el texto de una etiqueta <a> y también el atributo «href».
- En la línea 26 guardo la URL en el diccionario para luego poder meterlo en el csv con las instrucciones de las líneas 29,30, 31, 32. Lo interesante de ahí es el nombre del fichero CSV en la línea 30.
También veréis que hay algunas instrucciones precedidas del caracter «#», eso son comentarios y no se interpretan en la ejecución, pero podéis quitarlos porque casi todos están en prints que lo que harán será pintar por pantalla lo que contenga la variable que hay entre paréntesis. Podéis jugar con eso un poco para familiarizaros con el entorno.
Ahora ya solo nos queda ejecutar el script con la instrucción python empresas.py (o python3 empresas.py dependiendo de vuestro sistema) y observar la salida por consola en la que se irán mostrando las URLs que está analizando el script:
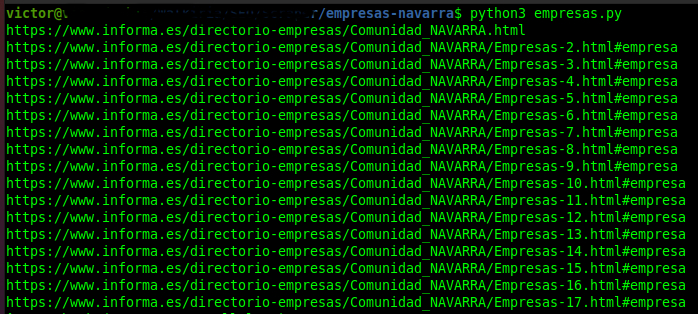
Y en el mismo directorio del script tendremos nuestro ansiado «urls_empresas_navarra.csv», que tendrá todas las URLs que nos interesa revisar.

¡Genial! Con esto acabamos con esta parte, ¡el primer script funciona!
Sacar información de las fichas de empresa
Hemos hecho lo más difícil, porque si has llegado hasta aquí ya sabes:
- Instalar Python.
- Instalar librerías de python.
- Saber buscar el contenido a scrapear con las etiquetas HTML adecuadas.
- Generar URLs para scrapear contenido.
- Crear un csv con el contenido que quieres.
Lo único que nos falta aquí es saber leer las URLs del csv y para cada una de ellas aplicar los mismos conocimientos que hemos aprendido anteriormente para sacar los datos que nos interesen. Esta parte del tutorial será menos específica porque es, básicamente, repetir conceptos. ¡Vamos allá!
Empezaremos abriendo una URL de las que tenemos en nuestro CSV para comprobar qué datos queremos sacar y cómo están organizados:

¡Genial! Otra vez los datos en una tabla, así que será bastante sencillo saber cómo sacarlos:
- Cada <tr> tiene dos elementos: un <th> que es el nombre del campo y un <td> que es el que tiene el dato que necesitamos.
Así que el script es tan sencillo como recorrer cada URL y buscar en la tabla todos los <td> que son los datos que nos interesan.
Pero hay un pequeño problema: no todas las empresas tienen todos los datos y nosotros necesitamos que el CSV esté organizado por columnas, y que en cada columna siempre esté el mismo dato (no queremos mezclar domicilio social con teléfono por ejemplo). Así que hay que hacer un pequeño «truqui» para que esto no nos ocurra.
Lo que haré será mirar en cada vuelta si el dato que me interesa ya está puesto en mi diccionario de la empresa (un objeto donde guardo los datos de la empresa). De este modo pondré un «-» si ese dato no está y lo pondré en su columna correspondiente. Tal vez este paso sea algo más avanzado y seguramente no se necesite hacer en casi ningún proyecto, pero yo lo dejo aquí explicado por si acaso alguien quiere aventurarse más. Esa función se resuelve en las líneas 7-18. Básicamente busca en el <td> cuyo <th> asociado se le pasa como parámetro (variable str) y devuelve el valor del <td> o «-» si no lo encuentra.
El resto del script es análogo al primero salvo en las líneas 22-29 que son las que hacen que se abra el csv urls_empresas_navarra.csv y asigne el valor de cada URL del csv a la variable url del script. Por cierto la línea 31 es para simular que la consulta se hace desde un navegador, ya que tuve problemas de baneo; con eso se solucionó.
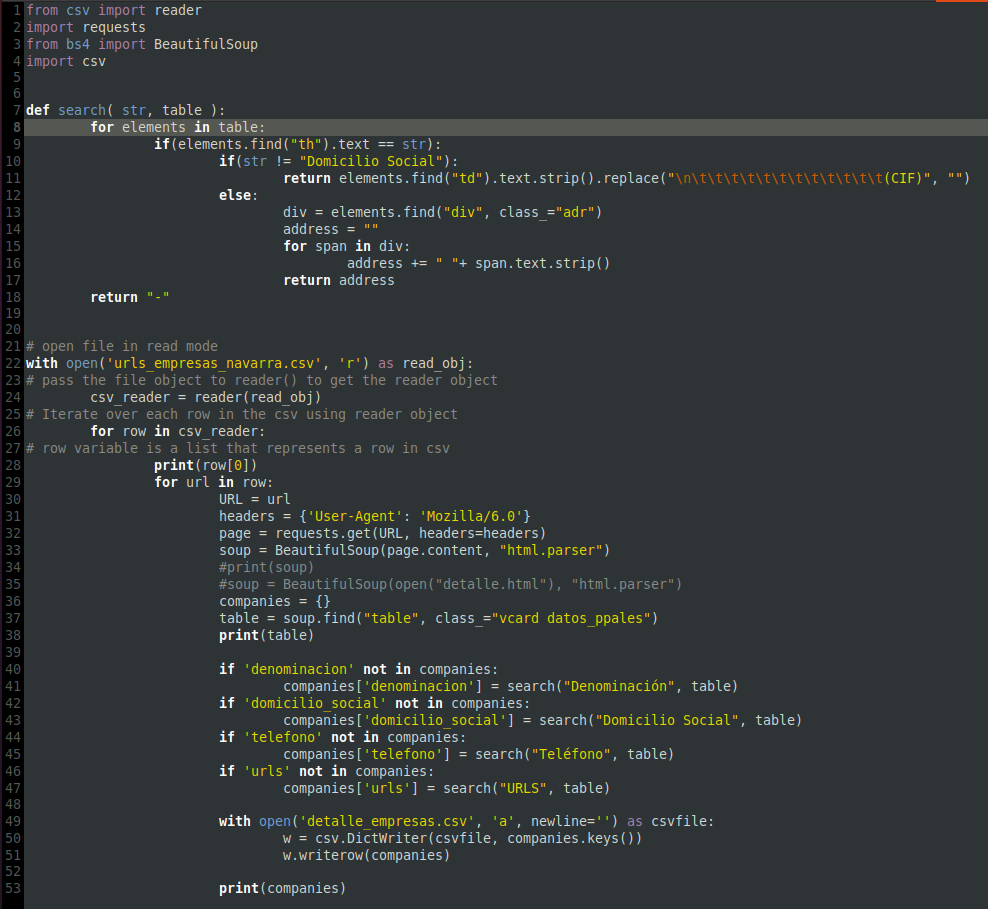
Os dejo el script aquí para copiar y pegar.
¡Perfecto! Pues una vez que lo ejecutemos tendremos un csv que se llamará detalle_empresas.csv en el mismo directorio con la siguiente pinta:

Bueno, falta por decir que los datos que elegí fueron el nombre, la dirección, el teléfono y la URL =).
¡Pues esto es todo! Hasta aquí la parte de raspado de información. Si queréis saber cómo hacer una web automática con un CSV podéis visitar mi blog de aprendiz de seo y ver el ejemplo que tengo con la automática de afiliación de Amazon. Para cualquier duda o consulta me tenéis por aquí o por mi canal de Telegram.
¡Un saludo!

Buenas
Tu código me ha ayudado mucho, pese a no ser programador lo pude aplicar sin problemas, he tenido algunas dificultades para obtener datos desde etiquetas div, me podrías ayudar con eso, muchas gracias.-
¡Hola! en principio todas las etiquetas se deben leer igual, normalmente por clase CSS o por nombre de la etiqueta. Si puedes dar más información acerca de cuál es el problema seguramente podamos afinar más con la ayuda. ¡Un saludo!
hola esta muy buena tu explicación, peor me salió el siguiente error
AttributeError Traceback (most recent call last)
Input In [43], in ()
15 soup = BeautifulSoup(page.content, ‘html.parser’)
16 table = soup.find(‘table’, class_=’empresas_directorio’)
—> 17 rows = table.find_all(‘tr’)
18 i = 0;
19 for row in rows:
AttributeError: ‘NoneType’ object has no attribute ‘find_all’
Hola, gracias por tu comentario.
En principio el error que da es que no encuentra la tabla cuya clase es «empresas_directorio». Hay que mirar si es que ha cambiado la estructura del sitio y ya no hay ninguna tabla con esa clase. Por lo que he visto en el enlace https://www.informa.es/directorio-empresas/Comunidad_NAVARRA.html sigue estando, así que no sé si estás buscando en una URL que no es y por eso te da el error. Necesito algún dato más para poder ayudarte.
¡Un saludo!
Genial Post Víctor gracias por recomendarmelo voy hacer pruebas a tope y haber si consigo aprender de una vez jajaja, como siempre ayudando a la gente espero ver algún contenido mas tuyo.